Chapter 6 From Qiime2 into R - Initial diagnostics
6.1 Introduction
In this chapter you will learn how to import Qiime2-produced ASV tables, taxonomy tables and tree files into R. For this exercise we will us publicly available FastQ files that were generated by a research group in Denmark. The files are available in the Sequence Read Archives (SRA) under accession number PRJNA645373.
Reference: [1] C. Jiang, S.J. McIlroy, R. Qi, F. Petriglieri, E. Yashiro, Z. Kondrotaite, P.H. Nielsen, Identification of microorganisms responsible for foam formation in mesophilic anaerobic digesters treating surplus activated sludge, Water Res. 191 (2021) 116779. https://doi.org/10.1016/j.watres.2020.116779.
Sample IDs
You decide on the samplesIDs before you start your library prep and sequencing. For this chapter we use a different dataset to the previous chatper and its sampleIDs are longer, e.g. “SRR12204258” and “SRR12204269”, compared to “PT-01”, “PT-02” in the previous chapter. It does not matter how you label each of your indexed samples as long as the IDs are unique. And each unique sample ID in the samplesheet.csv needs to match the sample IDs of the feature_table.qza. You may recall those IDs originate from your Miseq run and are the same sample IDs that are used on the loading manifest file to prepare the run. They subsequently are part of the FastQ filenames and flow through into any relevant Qiime2 data. If a sample ID does not match or if there is a different number of samples between these two input files, then phyloseq will complain.
Here the first three Sample IDs (“SRR12204258” and “SRR12204269” etc..) in the ASV table from this data set.:

ASV IDs
The same principle applies to each ID of the ASVs. The ASVs IDs have to match between the feature_table.qza and the taxonomy_silva.qza.
Following the first ASV IDs (Feature ID) and related taxon assignments in taxonomy_silva.qza of this dataset:

NOTE: After the denoising, taxonomic classification and tree alignments in Qiime2, I prefer to do all subsequent analysis in R. However, it is also possible to do much of the diversity analysis in Qiime2. In fact, some interesting plug-ins and functions in Qiime2 are not available as packages in R, hence for some specific tasks you may need to keep using Qiime2. It is up to the goals and preferences of the investigator.
Now let’s work in R!
Required files
samplesheet.tsv- same file that was used in the visualisation steps in Qiime2
feature_table.qza- if you created a phylogenetic tree from the sequences as described in the previous chapter then the ASVs in the feature table were filtered to match the ASVs in the tree. Hence the files was namedfeaturetable-insertiontree-filtered.qzato differentiate it.
taxonomy_silva.qza
insertion-tree.qza
6.2 Workflow
6.2.1 Packages
First install the required packages. Some packages are stored on ‘remote’ repositories such as GitHub, hence before you can install them you need helper packages such as remotes. Other packages, such as phyloseq are managed by BioConductor project. They provide their own package manager package for R called BiocManager, which helps to install from the same release.
Learn more about phyloseq here: https://joey711.github.io/phyloseq/
Both, remotes and BiocManager are already installed in the below example.
Once the packages are installed, load them into your working space.
# install.packages("remotes")
# if (!requireNamespace("BiocManager", quietly = TRUE))
# install.packages("BiocManager")
# remotes::install_github("jbisanz/qiime2R")
# BiocManager::install("phyloseq")
library(qiime2R) # to import qiime.qza into an R object
library(phyloseq) # To combine all relevant data objects into one object for easy data management
library(tidyverse) # Compilation of packages for data management
library(stringr) # to change some of the strings in taxonomic names
library(vegan) # A commonly used package for numerical ecology
6.2.2 Import qiime-files and create a phyloseq object
Now that packages are loaded we can import the Qiime2 .qza and the .tsv files. The aim is to import everything as R objects, which are then combined into one phyloseq object. Once we have a phyloseq object, any filtering and visualisations can be run from the one object.
In the previous chapter, we used a samplesheet.tsv to visualise and summarise the feature_table.qza. That exact same samplesheet.tsv is imported here and slightly changed to make it phyloseq friendly. In this example, all relevant Qiime2 outputs were copied into a folder named ‘qiimefiles’.
# Sample sheet
metadata <- read_tsv("qiimefiles/samplesheet.tsv") # lets call the R object 'metadata' to reflect its purpose
# Inspect the metadata object. The second row is qiime-specific information and has to be removed.
metadata2 <- metadata[c(2:nrow(metadata)),] %>% # remove the top row (q2:types..etc)and convert characters to factors
mutate_all(type.convert) %>%
mutate_if(is.factor, as.character) %>% # reformatting columns to avoid any problems with factors at this stage
as_tibble() %>%
column_to_rownames("#SampleID") # this puts the column "#SampleID" as rownames
# str(metadata2) # use the `str` command to inspect the data
# Then decide which of the columns you want to be factors and in which order these factors should go. This will determine the order in which ggplot will plot them. You can include the levels = c("level1", "level"...) command to determine the order, which is not done here.
metadata2 <- metadata2 %>%
mutate(Reactor = factor(Reactor)) %>% # replace column Reactor with the same values but made a factor.
mutate(Location = factor(loc)) # create a new column 'Location', which is a factor of 'loc'
# Qiime import
SVs <- qiime2R::read_qza("qiimefiles/featuretable-insertiontree-filtered.qza")
ASVtable <- as.data.frame(SVs$data) # extract the data table, this has to be a dataframe
# Taxonomy
taxonomy <- qiime2R::read_qza("qiimefiles/taxonomy_silva.qza") # import the qiime object
taxonomy <- taxonomy$data # extract the taxonomy data
## re-format the taxonomy file to split the taxonomy into columns
## remove the confidence column
taxtable <- taxonomy %>% as_tibble() %>%
separate(Taxon, sep=";", c("Kingdom","Phylum","Class","Order","Family","Genus","Species")) %>%
dplyr::select(-Confidence) %>%
column_to_rownames("Feature.ID") %>%
as.matrix()
# Tree
tree <- read_qza("qiimefiles/insertion-tree.qza")
tree <- tree$data #extract data
# Create the phyloseq object
ps <-phyloseq(
otu_table(ASVtable, taxa_are_rows = T),
sample_data(metadata2),
phyloseq::tax_table(taxtable),
phyloseq::phy_tree(tree)
)
# ps (not run)
# phyloseq-class experiment-level object
# otu_table() OTU Table: [ 4218 taxa and 51 samples ]
# sample_data() Sample Data: [ 51 samples by 14 sample variables ]
# tax_table() Taxonomy Table: [ 4218 taxa by 7 taxonomic ranks ]
# phy_tree() Phylogenetic Tree: [ 4218 tips and 4217 internal nodes ]
# remove things out of the R environment you dont need.
rm(metadata, metadata2, SVs, taxonomy, taxtable, tree, ASVtable)
## Remove those annoying short codes in front of taxa names (i.e. p__ etc) as they
## dont look good in visualisation
tax_table(ps)[, "Kingdom"] <- str_replace_all(tax_table(ps)[, "Kingdom"], "d__", "")
tax_table(ps)[, "Phylum"] <- str_replace_all(tax_table(ps)[, "Phylum"], " p__", "")
tax_table(ps)[, "Class"] <- str_replace_all(tax_table(ps)[, "Class"], " c__", "")
tax_table(ps)[, "Order"] <- str_replace_all(tax_table(ps)[, "Order"], " o__", "")
tax_table(ps)[, "Family"] <- str_replace_all(tax_table(ps)[, "Family"], " f__", "")
tax_table(ps)[, "Genus"] <- str_replace_all(tax_table(ps)[, "Genus"], " g__", "")
tax_table(ps)[, "Species"] <- str_replace_all(tax_table(ps)[, "Species"], " s__", "")From the output of the ps object we can see that there are 4281 ASVs in 51 samples and associated with 14 variables in the metadata.
If you wish, you can access each individual data set from the ps object with functions otu_table(ps)@.Data, sample_data(ps) tax_table(ps)@.Data or phy_tree(ps). This can become handy if you want to change something, such as adding columns to the sample_data or changing them to a factor etc..
ASVs <- otu_table(ps)@.Data
metadata <- data.frame(sample_data(ps))
taxtable <- data.frame(tax_table(ps)@.Data)
tree <- phy_tree(ps)
# Inspect individual objects in your own time.
6.2.3 Save the ps object as an .rds file into your working directory
Optional
This step allows you to save and store the R object as a RDS file and load it back into any future R environment, should you require it. This would be helpful if your workflow is separated into different Rscripts and you want to just load in the RDS file instead of having to import qiime files and create the phyloseq object every time.
6.2.4 Initial filtering
Keep the orginal ps object unchanged. Create new objects for subsequent filtering steps.
Often we simply filter out any ASVs that have less than x number of reads and are present in less than x number of samples. This helps to reduce noise and the overload of zeros in the dataset, which some differential abundance tests can’t deal with. Perhaps, it also helps with removing ASVs that were incorrectly denoised with DADA2 in the first place. However, it also means that rare ASVs with a low prevalence are not considered. So filtering has to be done with consideration to the intended analysis.
Then filter out any phyla that came up as uncharacterized and taxa that came up as mitochondria and chloroplast.
# filter as needed. This will be your final otu-table.
# Although you can still filter for specific analysis if needed.
# minimum of reads per feature
ps.flt = prune_taxa(taxa_sums(ps) >= 5, ps) #minimum reads per feature
# ps.flt (not run)
# phyloseq-class experiment-level object
# otu_table() OTU Table: [ 3911 taxa and 51 samples ]
# sample_data() Sample Data: [ 51 samples by 14 sample variables ]
# tax_table() Taxonomy Table: [ 3911 taxa by 7 taxonomic ranks ]
# phy_tree() Phylogenetic Tree: [ 3911 tips and 1694 internal nodes ]
#filter any "NA"-phyla that have not been classified i.e.
# contain nothing in the phylum column of the taxtable (just a <NA>)
ps.flt = subset_taxa(ps.flt , !is.na(Phylum) & !Phylum %in% c(""))
# ps.flt (not run)
# phyloseq-class experiment-level object
# otu_table() OTU Table: [ 3892 taxa and 51 samples ]
# sample_data() Sample Data: [ 51 samples by 14 sample variables ]
# tax_table() Taxonomy Table: [ 3892 taxa by 7 taxonomic ranks ]
# phy_tree() Phylogenetic Tree: [ 3892 tips and 1687 internal nodes ]
# Filter out non-bacteria, mitochondia and chloroplast taxa
ps.flt <- ps.flt %>%
subset_taxa(Kingdom == "Bacteria" & Family != "Mitochondria" & Class != "Chloroplast")
# ps.flt (not run)
# phyloseq-class experiment-level object
# otu_table() OTU Table: [ 3853 taxa and 51 samples ]
# sample_data() Sample Data: [ 51 samples by 14 sample variables ]
# tax_table() Taxonomy Table: [ 3853 taxa by 7 taxonomic ranks ]
# phy_tree() Phylogenetic Tree: [ 3853 tips and 1673 internal nodes ]
# We can filter more for running beta diversity or differential abundance analysis later. This will be shown in later chapters
# For example:
# minimum presence in x% of samples (51 * 0.04 = 2 samples)
# ps.flt = filter_taxa(ps.flt, function(x) sum(x > 0) > (0.04*length(x)), TRUE)
# Would result in
# phyloseq-class experiment-level object
# otu_table() OTU Table: [ 1674 taxa and 51 samples ]
# sample_data() Sample Data: [ 51 samples by 14 sample variables ]
# tax_table() Taxonomy Table: [ 1674 taxa by 7 taxonomic ranks ]
# phy_tree() Phylogenetic Tree: [ 1674 tips and 1673 internal nodes ]
6.2.5 Proportion of ASVs identified
Check what proportion of ASVs could be identified on phylum and genus-level. This is best done with the handy phyloseq function ntaxa(), which gives the number of taxa present in the phyloseq object.
This will indicate how many reads you would be discarding, in case you remove ASVs, which were not assigned a taxon.
It is also an indicator of how well the database you have been using (e.g. Silva here) has performed.You could compare that with other databases if you wish.
# percent of phyla identified
ps.flt = subset_taxa(ps , !is.na(Phylum) & !Phylum %in% c(""))
# percent of phyla identified
ntaxa(ps.flt) / ntaxa(ps)## [1] 0.9947843ps.flt = subset_taxa(ps , !is.na(Genus) & !Genus %in% c(""))
# percent of genera identified
ntaxa(ps.flt) / ntaxa(ps)## [1] 0.9402566.2.6 Rarefaction curve
Check if you cover enough depth for diversity analyses. Some samples may have low species richness, including a negative or samples that failed during PCR for example. The rarefaction curve will help assess which samples you may have to exclude from subsequent diversity calculations. It also provides a general view if samples cover enough of the potential richness (Number of ASVs).
The curve shows you the number of ‘Species’ (i.e. ASVs) on the y axis and the total reads on the x axis for each sample. So basically, it shows how rich each sample is and indicates if the number of reads that are captured in a samples covers enough of the ASVs. If the curve flattens, it indicates that the sample would not get any richer even with more reads…
I typically use the rarefaction curve to check if there are samples that need removing before establishing alpha diversity metrics. In this example, the vertical line helps identify the sample with lowest number of reads. We can check that by running min(colSums(otu_table(ps.flt))), which tells us that they are 9690 reads in the sample with lowest reads. If this sample is kept in and we measure subsequent alpha diversity metrics, where each of the sample-reads are randomly resampled to the lowest read-number (here 9690), then we may not capture the diversity of samples with higher richness. The grey horizontal lines indicate how much richness we may lose if we include the sample with lowest number of reads (the difference between grey horizontal line and the curve of each sample at the highest number of reads on x-axis).
vegan::rarecurve(data.frame(t(otu_table(ps.flt))),
step=200,
sample = min(colSums(otu_table(ps.flt))),
label = FALSE,
xlab = "Sample Size after filtering") 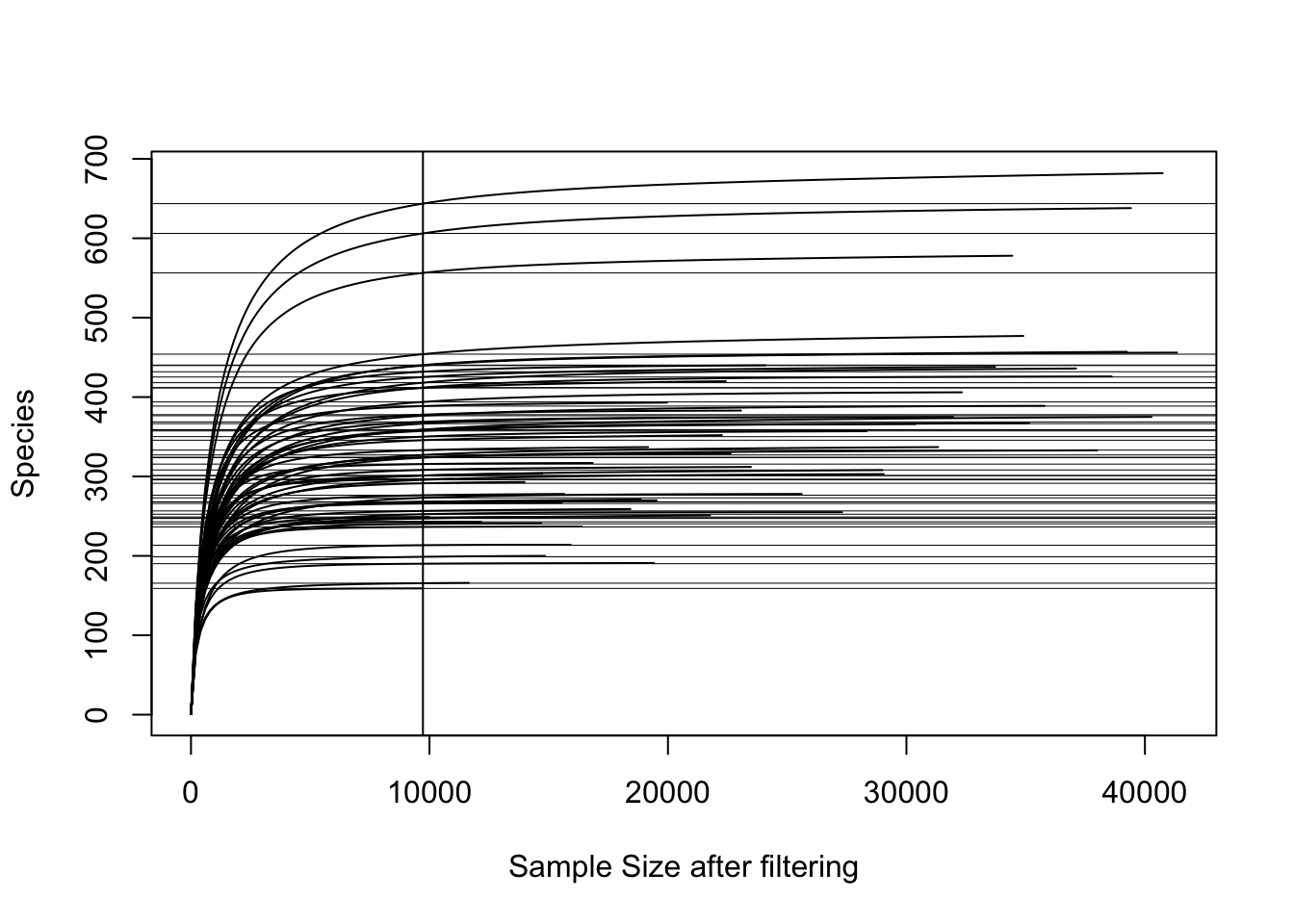
## [1] 41342## [1] 9726# Filtering options
# filter options (not run), you can filter out specific sample or treatments from the phyloseq objects.
# `%notin%` = Negate(`%in%`) # create a %notin% filter operator for filtering
# Filtering out treatments, e.g. any sample that was labeled "Negative" in the metadata
# ps.flt.flt <- prune_samples(sample_data(ps.flt)$Treatment %notin% c("Negative"), ps.flt)
# Filtering out any taxa that have zero reads because they were only present in the removed samples.
# ps.flt.flt <- prune_taxa(taxa_sums(ps.flt.flt) != 0, ps.flt.flt)Once you identified the samples you would like to remove (e.g. samples with too few reads), you can filter out these specific samples or treatments from the phyloseq objects. For example, with the prune_samples(sample_data(ps.flt)$Treatment %notin% c("Negative"), ps.flt) command here we would sample out any samples labeled as “Negative” in the metadata. Afterwards make sure to sample out any taxa that now contain zero reads because they were only present in the removed samples. Perhaps, create new phyloseq objects to differentiate from your different filtered object ps.flt.flt <- prune_taxa(taxa_sums(ps.flt) != 0, ps.flt). See also Chapter 8 where the phyloseq object is pre-filtered before ggplotting.
In this example, we are keeping the sample with lowest reads. No further filtering required at this stage.
6.2.7 Prevalence table
Create a prevalence table to get an overview of phyla with low to high prevalence.
The output is a dataframe showing all phyla in order of total abundance. The mean prevalence defines how often the phylum appears across all samples on average. E.g. a mean prevalence of 10.22 means that ASVs in this phylum were present on average in 10.22 samples. Higher values indicates a ‘core’ relevance to the sum of samples.
This table is handy to decide if you want to remove certain phyla from some visualisations as they may not contribute to the overall analysis. It also allows for a comparison with filtered and unfiltered data for due diligence. Here it is apparent that phyla that were unclassified (i.e. 3522 / sum(phyloseq::otu_table(ps)) * 100 = 0.27%. Chances are that these NA sequences may just be noise and may not represent biological relevant amplicons. Hence, I would keep them out of any further analysis.
However, in environments where you get higher contributions of unknown amplicons, it may indicate that the taxonomic database does not capture your samples well. In that case it would be wise to keep the NAs in for measuring alpha and beta diversity.
prevalencedf = apply(X = phyloseq::otu_table(ps.flt),
MARGIN = 1,
FUN = function(x){sum(x > 0)})
prevalencedf = data.frame(Prevalence = prevalencedf ,
TotalAbundance = taxa_sums(ps.flt),
phyloseq::tax_table(ps.flt))
prevalencedf <- prevalencedf %>%
dplyr::group_by( Phylum ) %>% # choose phylym level
dplyr::summarise(Mean_prevalence = mean(Prevalence),
Total_abundance = sum(TotalAbundance)) %>%
dplyr::mutate(Rel_abundance = (Total_abundance / sum(Total_abundance) *100)) %>%
arrange(desc(Total_abundance)) %>%
dplyr::mutate(Cumulated = cumsum(Rel_abundance))
# print table from highest to lowest abundance
knitr::kable(prevalencedf, digits = 1) %>%
kableExtra::kable_styling(bootstrap_options = c("striped", "condensed", "responsive"), full_width = F, font_size = 10)| Phylum | Mean_prevalence | Total_abundance | Rel_abundance | Cumulated |
|---|---|---|---|---|
| Chloroflexi | 4.9 | 228035 | 18.1 | 18.1 |
| Bacteroidota | 4.5 | 199720 | 15.9 | 34.0 |
| Firmicutes | 4.3 | 179454 | 14.3 | 48.3 |
| Actinobacteriota | 5.1 | 161701 | 12.9 | 61.1 |
| Proteobacteria | 4.1 | 151650 | 12.1 | 73.2 |
| Desulfobacterota | 4.9 | 57139 | 4.5 | 77.7 |
| Synergistota | 6.7 | 51049 | 4.1 | 81.8 |
| Cloacimonadota | 6.7 | 43842 | 3.5 | 85.3 |
| Acidobacteriota | 3.8 | 35158 | 2.8 | 88.1 |
| Thermotogota | 10.2 | 33489 | 2.7 | 90.7 |
| Spirochaetota | 4.5 | 24593 | 2.0 | 92.7 |
| Verrucomicrobiota | 3.0 | 16246 | 1.3 | 94.0 |
| Fermentibacterota | 35.0 | 14812 | 1.2 | 95.2 |
| Patescibacteria | 3.2 | 14454 | 1.1 | 96.3 |
| Caldatribacteriota | 5.3 | 8934 | 0.7 | 97.0 |
| Planctomycetota | 2.4 | 5158 | 0.4 | 97.4 |
| Armatimonadota | 2.6 | 4462 | 0.4 | 97.8 |
| Marinimicrobia_(SAR406_clade) | 20.0 | 3818 | 0.3 | 98.1 |
| Hydrogenedentes | 4.0 | 3411 | 0.3 | 98.4 |
| Nitrospirota | 8.8 | 2853 | 0.2 | 98.6 |
| SAR324_clade(Marine_group_B) | 3.3 | 2622 | 0.2 | 98.8 |
| WS1 | 3.6 | 2559 | 0.2 | 99.0 |
| Campilobacterota | 3.9 | 2465 | 0.2 | 99.2 |
| Fibrobacterota | 2.7 | 1874 | 0.1 | 99.3 |
| Myxococcota | 2.8 | 1366 | 0.1 | 99.5 |
| Bdellovibrionota | 2.4 | 1133 | 0.1 | 99.5 |
| Caldisericota | 3.6 | 1071 | 0.1 | 99.6 |
| WPS-2 | 2.7 | 897 | 0.1 | 99.7 |
| Sumerlaeota | 3.6 | 686 | 0.1 | 99.8 |
| Cyanobacteria | 9.0 | 647 | 0.1 | 99.8 |
| Fusobacteriota | 2.9 | 565 | 0.0 | 99.9 |
| Coprothermobacterota | 2.8 | 511 | 0.0 | 99.9 |
| Gemmatimonadota | 2.7 | 304 | 0.0 | 99.9 |
| Elusimicrobiota | 2.8 | 225 | 0.0 | 99.9 |
| CK-2C2-2 | 4.0 | 162 | 0.0 | 99.9 |
| Methylomirabilota | 4.0 | 159 | 0.0 | 100.0 |
| Dependentiae | 1.9 | 90 | 0.0 | 100.0 |
| Latescibacterota | 2.0 | 89 | 0.0 | 100.0 |
| Zixibacteria | 5.0 | 74 | 0.0 | 100.0 |
| Sva0485 | 2.0 | 69 | 0.0 | 100.0 |
| Acetothermia | 2.0 | 59 | 0.0 | 100.0 |
| WS4 | 1.2 | 46 | 0.0 | 100.0 |
| Hydrothermae | 1.0 | 26 | 0.0 | 100.0 |
| Deinococcota | 1.0 | 11 | 0.0 | 100.0 |
| FCPU426 | 1.0 | 3 | 0.0 | 100.0 |
| Margulisbacteria | 1.0 | 3 | 0.0 | 100.0 |
| MBNT15 | 1.0 | 2 | 0.0 | 100.0 |
## Compare with the original, unfiltered ps object
prevalencedf = apply(X = phyloseq::otu_table(ps),
MARGIN = 1,
FUN = function(x){sum(x > 0)})
prevalencedf = data.frame(Prevalence = prevalencedf,
TotalAbundance = taxa_sums(ps),
phyloseq::tax_table(ps))
prevalencedf <- prevalencedf %>%
dplyr::group_by( Phylum ) %>% # choose phylym level
dplyr::summarise(Mean_prevalence = mean(Prevalence),
Total_abundance = sum(TotalAbundance)) %>%
dplyr::mutate(Rel_abundance = (Total_abundance / sum(Total_abundance) *100)) %>%
arrange(desc(Total_abundance)) %>%
dplyr::mutate(Cumulated = cumsum(Rel_abundance))
knitr::kable(prevalencedf, digits = 1) %>%
kableExtra::kable_styling(bootstrap_options = c("striped", "condensed", "responsive"),full_width = F, font_size = 10)| Phylum | Mean_prevalence | Total_abundance | Rel_abundance | Cumulated |
|---|---|---|---|---|
| Chloroflexi | 4.9 | 228276 | 17.6 | 17.6 |
| Bacteroidota | 4.5 | 202022 | 15.5 | 33.1 |
| Firmicutes | 4.3 | 197782 | 15.2 | 48.3 |
| Actinobacteriota | 5.0 | 165791 | 12.8 | 61.1 |
| Proteobacteria | 4.0 | 161897 | 12.5 | 73.5 |
| Desulfobacterota | 4.8 | 57187 | 4.4 | 77.9 |
| Synergistota | 6.5 | 51227 | 3.9 | 81.9 |
| Cloacimonadota | 6.4 | 45296 | 3.5 | 85.4 |
| Acidobacteriota | 3.8 | 35318 | 2.7 | 88.1 |
| Thermotogota | 10.2 | 33489 | 2.6 | 90.7 |
| Spirochaetota | 4.4 | 25028 | 1.9 | 92.6 |
| Verrucomicrobiota | 3.0 | 16649 | 1.3 | 93.9 |
| Fermentibacterota | 35.0 | 14812 | 1.1 | 95.0 |
| Patescibacteria | 3.1 | 14501 | 1.1 | 96.1 |
| Caldatribacteriota | 5.3 | 8934 | 0.7 | 96.8 |
| Planctomycetota | 2.4 | 5478 | 0.4 | 97.2 |
| Armatimonadota | 2.6 | 4462 | 0.3 | 97.6 |
| Marinimicrobia_(SAR406_clade) | 20.0 | 3818 | 0.3 | 97.9 |
| NA | 3.6 | 3522 | 0.3 | 98.1 |
| Hydrogenedentes | 4.0 | 3411 | 0.3 | 98.4 |
| Nitrospirota | 8.8 | 2853 | 0.2 | 98.6 |
| Campilobacterota | 4.2 | 2710 | 0.2 | 98.8 |
| SAR324_clade(Marine_group_B) | 3.3 | 2622 | 0.2 | 99.0 |
| WS1 | 3.6 | 2559 | 0.2 | 99.2 |
| Fibrobacterota | 2.8 | 1942 | 0.1 | 99.4 |
| Myxococcota | 2.7 | 1369 | 0.1 | 99.5 |
| Bdellovibrionota | 2.4 | 1133 | 0.1 | 99.6 |
| Caldisericota | 3.6 | 1071 | 0.1 | 99.6 |
| WPS-2 | 2.7 | 897 | 0.1 | 99.7 |
| Sumerlaeota | 3.6 | 686 | 0.1 | 99.8 |
| Cyanobacteria | 9.0 | 647 | 0.0 | 99.8 |
| Fusobacteriota | 2.9 | 565 | 0.0 | 99.9 |
| Coprothermobacterota | 2.8 | 511 | 0.0 | 99.9 |
| Gemmatimonadota | 2.7 | 304 | 0.0 | 99.9 |
| Elusimicrobiota | 2.8 | 225 | 0.0 | 99.9 |
| CK-2C2-2 | 4.0 | 162 | 0.0 | 100.0 |
| Methylomirabilota | 4.0 | 159 | 0.0 | 100.0 |
| Dependentiae | 1.8 | 94 | 0.0 | 100.0 |
| Latescibacterota | 2.0 | 89 | 0.0 | 100.0 |
| Zixibacteria | 5.0 | 74 | 0.0 | 100.0 |
| Sva0485 | 2.0 | 69 | 0.0 | 100.0 |
| Acetothermia | 2.0 | 59 | 0.0 | 100.0 |
| WS4 | 1.2 | 46 | 0.0 | 100.0 |
| Hydrothermae | 1.0 | 26 | 0.0 | 100.0 |
| Deinococcota | 1.0 | 11 | 0.0 | 100.0 |
| FCPU426 | 1.0 | 3 | 0.0 | 100.0 |
| Margulisbacteria | 1.0 | 3 | 0.0 | 100.0 |
| MBNT15 | 1.0 | 2 | 0.0 | 100.0 |
6.2.8 Export ASV and taxa tables to Excel
This might be useful if you would like to share your abundance and taxa tables with someone that does not use R.
# extract ASV table from ps object
ASVs <- data.frame(otu_table(ps.flt)) %>%
rownames_to_column("FeatureID")
# extract taxonomy table from ps object
taxtable <- data.frame(tax_table(ps.flt))
# combine the taxonomy levels into one colum, separated by a ;
taxtable <- taxtable %>%
rownames_to_column("FeatureID") %>% as_tibble() %>%
unite(Taxon, sep=";", c("Kingdom","Phylum","Class","Order","Family","Genus","Species"))
# combine ASVs and taxatable into one object
ASVTable <- ASVs %>% left_join(taxtable, by = "FeatureID")
# write .csv file
# write.csv(ASVTable, "ASVTable.csv") not runNote:
This code is an amalgamation from various sources. Apart from putting it together into this workflow I do not take credit for it.